Climbing the peak
Scenario
In your usual sizing efforts you need to know the peak usage% for a certain workload and server(s). What is the right averaging time to capture this peak? Let’s see possible choices.
Too long averaging time
Averaging Time = 500 min. Peak usage% = 50%.
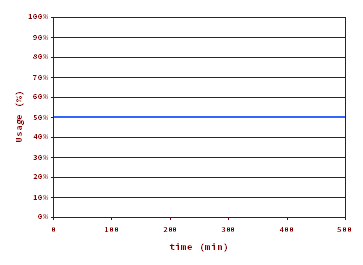
Total loss of finer details. Does this really mean that the usage% has been the same for the 500 min? You, like me, don’t believe that!
Too short averaging time
Averaging Time = 10 s. Peak usage% = 100%.
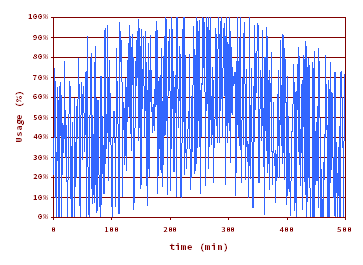
Too much detail. This may be good for performance analysis, but it is confusing for sizing. Spikes goes up to usage%=100%, meaning that for 10 s -the averaging time- in a row the server is 100% busy. But I wouldn’t consider that the server usage% is 100% for sizing purposes. If you do so you most probably are oversizing, a common (and safe) strategy by the way.
The right averaging time?
Averaging Time = 10 min. Peak usage% = 68%.
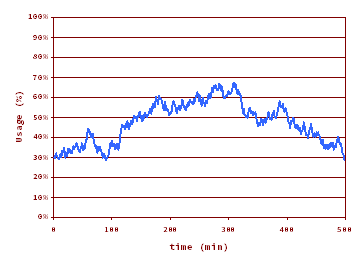
Eureka! This is the right amount of detail. In my point of view the right averaging time for OLTP lies somewhere between 10 min and 1 hour, depending on the workload, on the available data, and on the degree of tolerance to a high usage%.

