The upgrade sizing pitfall
The art of sizing is not exempt of pitfalls, and you must be aware of them if you want your sizing to be accurate and adequate. Let us talk about a typical scenario: a server upgrade.
All the metrics in sizing are measures of throughput, and this has an implication you must take into account: not always the service center (the server, here) with higher throughput capacity is better. What are you saying man?
Let's consider two servers, the base one and its intended upgrade:
- Base: single core server with a capacity (maximum throughput = bandwidth) of 1 tps (transaction per second). Therefore the transaction service time is 1 second.
- Upgrade: four core server with a capacity of 2 tps. Therefore the transaction service time is 2 seconds.
If you exclusively look at the throughput, B (2 tps) is better than A (1 tps). Period.
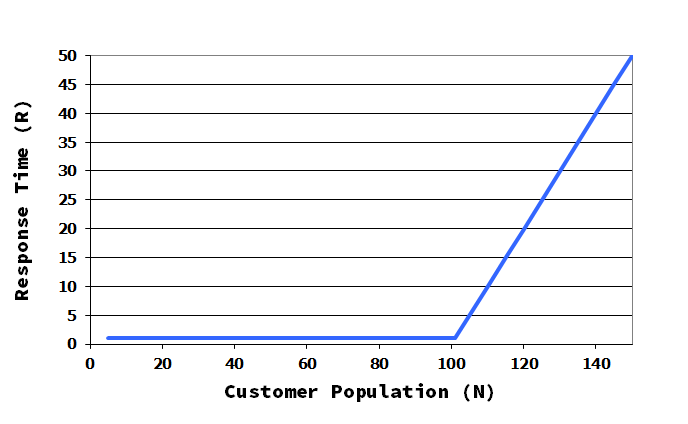
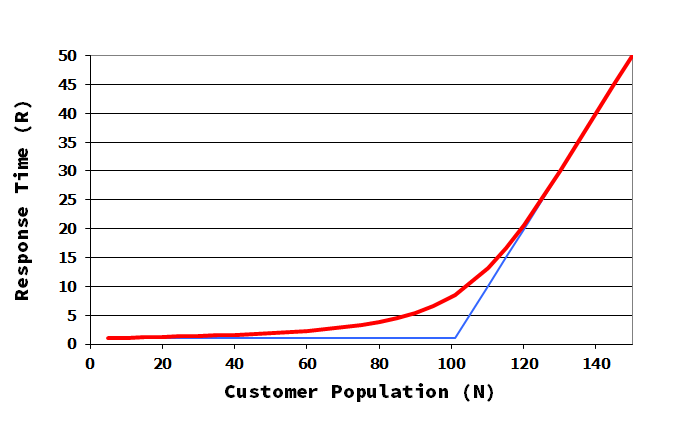
But from the response time perspective such a superiority must be revised. Let us graph the response time versus the number of users:

Figure: Best response time (average) versus the number of users, with a transaction think time of 30 seconds. Server A (base) in blue. Server B (upgrade) in red.
In the light load zone, that is, when there are no or few queued transactions, A is better than B. This is consequence of a better (lower) service time for server A. In the high load zone B is better than A. consequence of a better (higher) capacity (throughput). If the workload wanders in the light zone such an upgrade would be a bad idea.
So when you perform a sizing you must know wich point of view is relevant to your sizing exercise: the throughput or the response time. Don't fall in the trap. A higher capacity (throughput) server is not unconditionally better. For an upgrade server to be unconditionally better its capacity (throughput) must be higher and its service time lower.