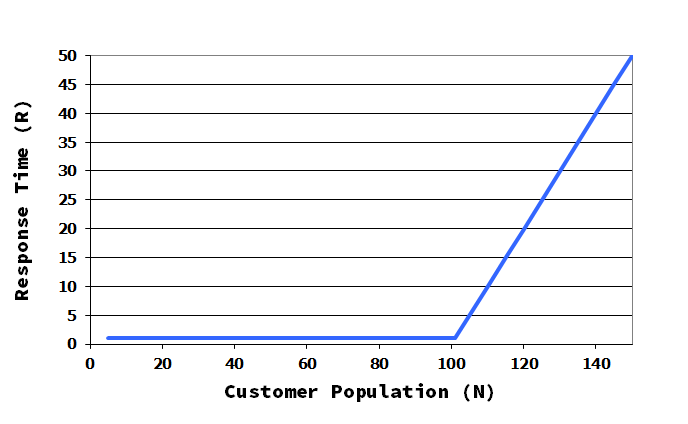
A certain transaction uses 1 ms of cpu time and 20 ms of IO time. With a think time of 10 s the system supports 550 users with a response time R below 1 s.
Now the same system is equipped with a faster storage where part of the data is placed. When this data replacement is automatic, the faster storage is acting as a cache. If the transaction finds the data in the cache the IO time is reduced to 5 ms. Otherwise the IO time remains to be 20 ms.
With a hit ratio of 10%, that is, one in ten IO accesses are served from the cache, the performance of the system improves in the following ways:
With the same customer population (550 users) now the average response time drops from 1 s to 0.20 s!
The user population may increase from 550 to 611 users to reach again the limit of 1 s of average response time.
|
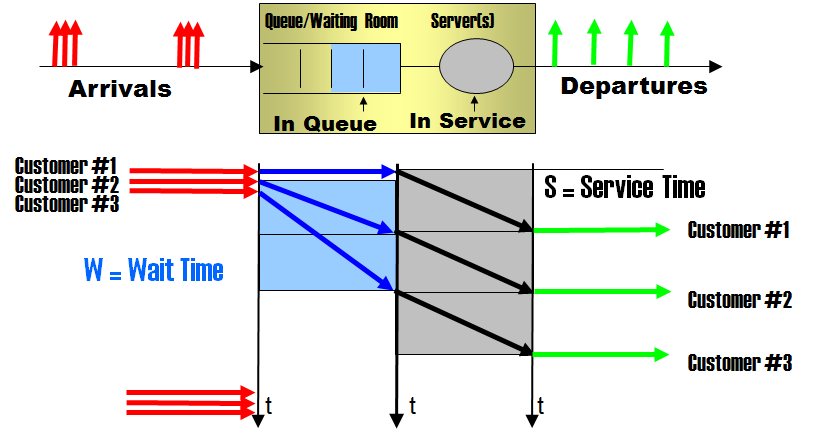
Let us build a reasonably simplified performance model for the caching in data tiering, a model suitable for a simple but illustrative performance analysis. A transaction "visits" the CPU, using C units of time (1 ms in the scenario), and "visits" the storage, using S units of time (20 ms in the scenario).
With a cache in place the same transaction may find the data in the cache -this is called a (cache) hit-, and in such fortunate case it doesn't have to visit the storage. This fast IO takes F units of time (5 ms in the scenario)
Two parameters to describe the cache effect:
α - efficiency (0 <= α <= 1), defined as α=(S-F)/S or, equivalently F=S(1-α).
h - hit ratio: (0 <= h <= 1), ratio of transactions that get their required data from the cache, typically proportional to its capacity.
KPI #1: Best Latency
Without the cache the best latency (response time) a transaction may achieve is Rmin=C+S units of time. With the cache in place, the best achievable latency reduces to R'min=C+F, corresponding to the transactions that get their IO from the cache.
In our scenario, the best latency with cache miss is 21 ms, and with cache hit is 6 ms.
KPI
|
No cache
|
With cache
|
Best Latency
|
C+S
|
hit: C+S(1-α)
miss: C+S
|
KPI #2: Bandwidth
Without the cache the bandwidth (best throughput) the system delivers is B=1/S, limited by the bottleneck device, the slow storage. With the cache in place the system is able to sustain a peak throughput of B'=B/(1-h) for h<α and B'=B/(h·(1-α)) for h>α .
In our scenario, the bandwidth without cache is 1/20 ms-1, that is 50 transactions per second. With cache the bandwidth increases 11% for a hit ratio h=10%, 25% for h=20%, and 100% for h=50%.
KPI
|
No cache
|
With cache
|
Bandwidth
|
B=1/S
|
B'=B/(1-h) if h<=1/(2-α)
B'=B/[h·(1-α)] if h>1/(2-α)
|
Here is a plot of the bandwidth gain with cache versus the hit ratio. The hit ratio that achieves the maximum bandwidth gain is h=1/(2-α), and the corresponding maximum gain is B'/B=(2-α)/(1-α).
Graph: bandwidth gain with cache (α=75%) versus the hit ratio
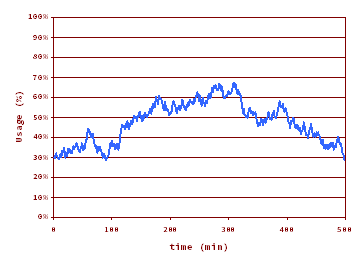
KPI #3: Response Time
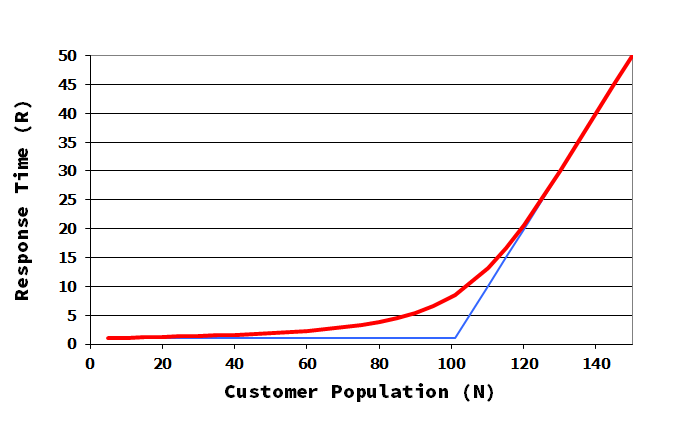
The impact of the presence of the cache in the response time signature of the system, that is, the graph response time versus the number of users interacting with the system, is twofold:
a displacement to the right due to the increase of the saturation population, the point that marks the change of phase, and
a decrease in the high load slope.
Graph: response time versus the number of users
The consequence of these is that the the cache reduces the response time, a reduction that is stronger in the high load zone. We must speak of averages here, as there are two response times now: one for transactions with IO is served from cache, and other for transactions with IO served from the slow storage.
In our scenario with a hit ratio of 10% the response time of the system drops from 1 s to 0.20 s with the same customer population (550 users).
KPI #4:Supported users
Looking at the response time signature from another point of view is clear that additional users may work in the system while keeping the same level of performance (response time limit).
In our scenario the user population may increase from 550 to 611 users to reach again the limit of 1 s of average response time (see above graph).
Side effects
These performance benefits of caching don't come for free. Apart from the evident monetary cost, think about the following
The CPU usage increases: the cache alleviates the load on the storage but increase the load on the CPU, because if the CPU gets the data faster, it has more work to do. This may displace other cpu intensive work that may be competing for the CPU.