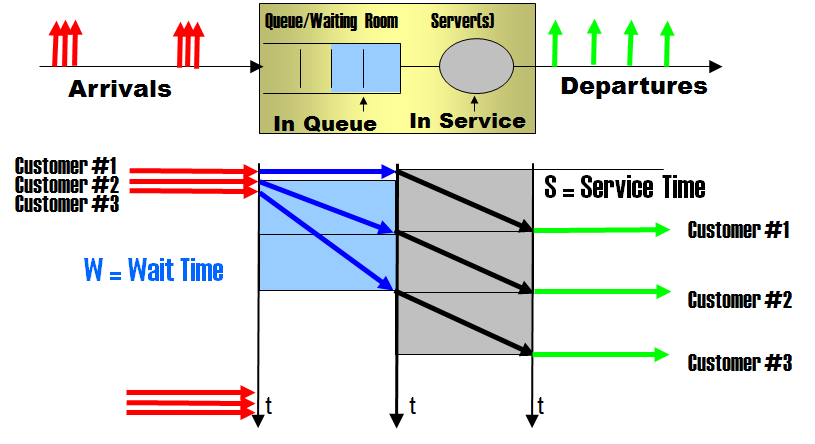
Wait time is lost time
I suppose everyone agrees with the sentence: wait time is lost time. Nobody likes or wants to wait. From the customer (requester) point of view wait time is, in general, badly tolerated.
But the service provider point of view is different. In general it would not provide ample capacity to eliminate any waits, given that the capacity has a cost and probably will remain idle out of peak times. An agreement/equilibrium must be reached.
How much do you have to wait?
Suppose you are a customer, arrive to a service center that has one worker, and find Q customers waiting in the queue ahead of you, and one customer being serviced. How much do you have to wait?
The response is simple: the remaining service time for the customer being serviced, plus the service time of the 1st customer in the queue, plus the service time for the 2nd customer in the queue,..., and so on until the last customer queued (the number Q). This results in the following expression for the waiting time (W) ():
S1 + S2 + ... + SQ <= W <= S0 + S1 + S2 + ... + SQ
|
If we make the simplifying assumption that the service time (S) is constant, that is, every customer spends the same amount of time receiving service, we have this simpler expression
Q · S <= W <= (Q+1) · S
|
and being the response time equal to the sum of the waiting time and the service time (R = W + S) we have
(Q+1) · S <= R <= (Q+2) · S
|
In the case of a service center that has m workers, and S constant, the bounds to the waiting and the response time are
S*INT(Q /m) <= W <= S+S*INT(Q /m)
|
and
S + S*INT(Q /m) <= R <= 2S + S*INT(Q /m)
|
where INT() is the integer part function.
So the waiting time depends on:
- The Service Time (S): If the service time, mine or of the customers ahead in the line, increases (decreases) the response time will increase (decrease) as well.
- The Number of Workers (m): If the number of workers increases (decreases) the wait time will decrease (increase) as the line will advance faster (slower).
- The number of queued customers (Q), that is, the number of waiting (queued) customers ahead of you. The bigger Q is the bigger the wait time is.
Practical cases
Hairdresser’s:
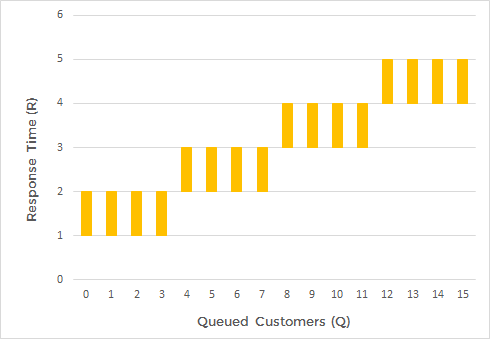
My hairdresser’s has the following performance values: a service time of 1 hour (S=1 h), and four hairdressers at work (m=4). When I arrive there, willing to get an haircut, there are 4 customers in the waiting room (Q=4).
I can easily derive that I'll have to wait between 1 and 2 hours, as 1*int(4/4)=1 and 1+1*int(4/4)=2. That is, the response time I will experience will be between 2 h and 3 h.
Here is the plot of the response time (R) interval against the number in the queue (Q):
Company Department:
In my company department jobs take one working day to be completed (S=1 day), and there are three equally qualified professionals working there (m=3). So when a new job arrives and "finds" a queue of 6 (Q=6), it may be concluded that the job requester must have to wait between 3 and 4 days to get his request serviced, as 1 + INT(6/3) <= R <= 2 + INT(6/3).
New blog URL: http://www.ibm.com/blogs/performance
Mirror blog: http://demystperf.blogspot.com