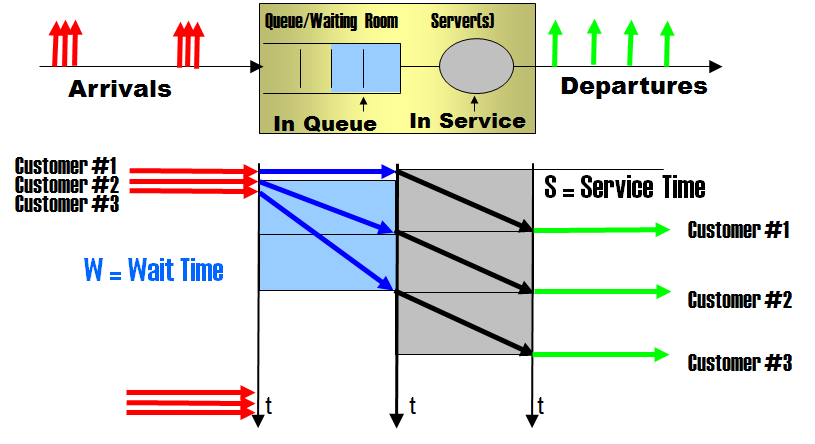
The SAPS benchmark fits very closely in the model analyzed in the post "Phases of the Response Time". In essence the benchmark is performed by progressively increasing the customer population, and monitoring the response time. When response time reaches 1 second, the measured throughput, as expressed in dialog steps per minute, is the SAPS value. The think time remains constant at 10 s.
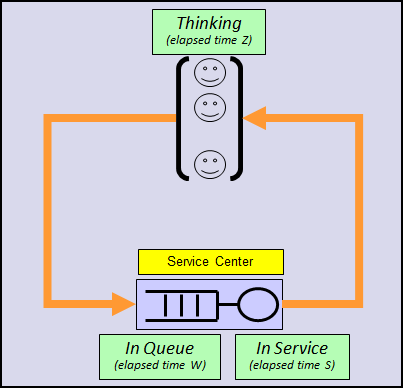
SAPS is a performance metric measuring throughput: 1 SAPS is 1 dialog step (a unit of work defined by SAP) per minute. This basically means 1 customer service per minute
Model Calibration
Let us consider, without loss of generality, the benchmark number 2014034, corresponding to an IBM POWER E870.

According to the benchmark certificate these are the measured values:
- m = 640, the number of concurrent HW threads,
- X = 26166000 ds/h = 436100 ds/min (SAPS).
- N = 79750, the number of users.
- R = 0.97 s, the average response time.
The service time is derived from those values:
- S = m/B = 0.088 s/ds.
As R>>S the system must be well above the saturation point. The saturation point N* is N*=m(1+Z/S)= 73323, and N, as stated in the benchmark certification, is 79750. Clearly N>N*, confirming the hypothesis that the system is operating well over the saturation point.
At this point we have our simple model well calibrated. To double check it, we can see that the response time predicted by our simple model would for a population of N=79750, the benchmark population, is 0.969s, while in the certification the response time in 0.97 s, a very close agreement!


Prognosis (Prediction)
The key benefit of having a simple model for studying the performance behavior of more complex systems is the prediction ability it gives to us. We ask and the model responds.
Question .- If the response time limit in the SAP benchmark were 2 s instead of 1 s, what would the system throughput (SAPS) be?
Answer.- Contrary to what some may think... it will remain almost the same! Being above the saturation point the model predicts the same throughput, equal to the maximum throughput (system bandwidth). The delta SAPS for this change will be very slight and not significant.
Question.- If response time limit in the SAP benchmark were 0.5 s instead of 1 s, what would the system throughput (SAPS) be?
Answer.- The response is the same as before: almost the same. A response time of 0.5 is also above the saturation point and this implies that the system throughput will be the same. In the real world there would be a non significative (negative) delta.
We've varied the response time limit by a wide margin, from -50% (here) to +100% (previous case) and the SAPS remain almost the same... I bet you wouldn't have said so before reading this article.
Question.- But...what changes then between current 1 s and new 0.5 s?
Answer.- The number of benchmark users needed to get to the response time limit, less in the 0.5s than in the 1s case.
Question.- With current benchmark definition and 90000 users, what will the expected response time?
Answer.- Looking at the (number of users, response time) graph above, you can conclude the response time will be around 2.4 s.